

This article is a guest-contribution by Lloyd Chandran, Founder & Lead Architect at Fincarna
Let me start with a confession: I’ve built more job processing systems than I care to admit, from the dark days of EJB timers to JMS queues, Spring Batch configurations, and even some bespoke batch frameworks that seemed like good ideas at the time.
At Fincarna, where we’re building a modern monetization platform for small and medium banks, I’ve learned that not every background job is created equal, and many seem to think they are.
Want to skip the intro and go immideatly to code-examples?
The Features That Actually Mattered for Us.
The ETL Trap: When Your Hammer Thinks Everything’s a Nail
Here’s the thing about Extract, Transform, Load frameworks (ETL), they’re fantastic when you’re actually doing ETL operations.
Need to pull customer data from three different legacy banking systems, massage it into something resembling modern JSON, and dump it into your data warehouse? Perfect. ETL frameworks absolutely crush it in these scenarios.
But what happens when your “job” is actually sending a push notification to a customer about their overdraft fee?
Or calculating interchange fees in real-time? Or handling a webhook that needs to apply a new fee structure immediately?
Suddenly, your elegant Reader-Writer-Processor pipeline feels like using a forklift to hang a picture frame.
Sure, it’ll work, but you’re going to make a mess and probably over-engineer the hell out of something that should be simple.
And don’t even get me started on trying to make these behemoth frameworks “near real-time”, you’ll end up with the infrastructure budget of a Fortune 500 company and the maintenance headaches to match.
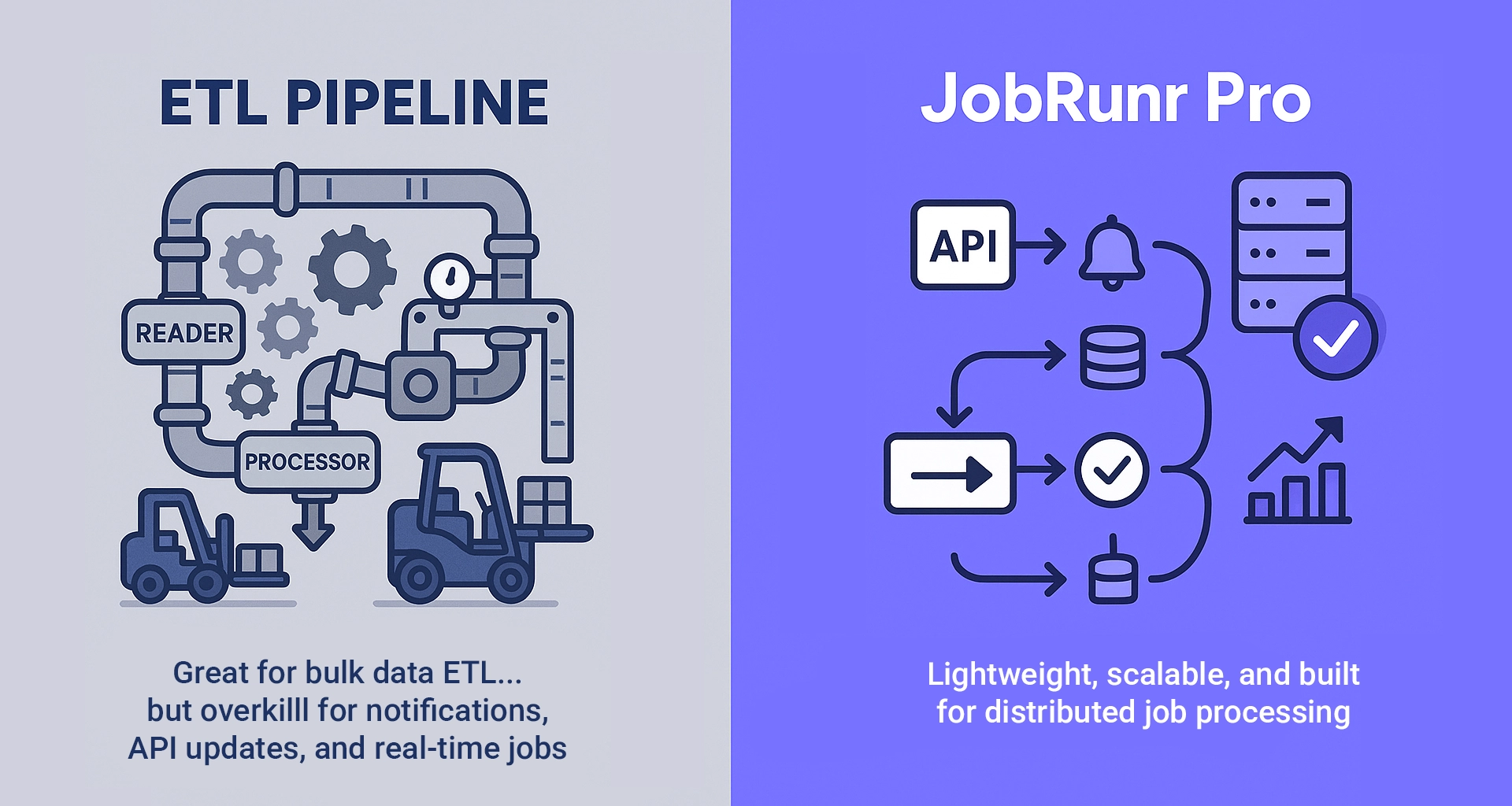
When Your Framework Becomes Your Boss
I’ve seen too many codebases where the job framework’s opinions became architectural constraints.
You know the type - where every simple task gets shoehorned into a three-step dance of reading, processing, and writing, even when all you want to do is call an API and update a flag.
At Fincarna, we process everything from account reconciliations (hello, ETL!) to instant fee notifications (definitely not ETL). The last thing I want is my job framework forcing me to think in terms of “chunks” and “item processors” when I’m just trying to send a fee notification or update an account balance. Sometimes the best design is the one that gets out of your way.
We discuss the importance of choosing the right tool for the job in our article on modern alternatives to Quartz.
Scaling: The Art of Not Breaking Things
In fintech, scaling isn’t just about handling more load, it’s about handling more load without accidentally charging the same fee twice or missing a revenue opportunity.
The stakes are a bit higher than your average e-commerce site.
What I love about JobRunr Pro is that scaling feels natural. Need more throughput? Add more workers. Need to handle spikes? The system adapts. No need to become a distributed systems PhD just to process more background jobs without losing money.
Want to learn more about K8S autoscaling, check out the guide Autoscale your JobRunr application deployed on Kubernetes or our blogpost Optimizing Cost and Performance on Kubernetes: Scale Java Workloads with JobRunr Metrics
The beauty is in the simplicity: your jobs scale horizontally without you having to think about partitioning strategies or coordination protocols. Because honestly, I’d rather spend my time building features that make banks money than debugging why my job queue decided to process everything twice.
Database Sympathy: Treating Your DB Like It Has Feelings
Here’s where many job frameworks reveal their database ignorance. They’ll happily slam your database instance with hundreds of concurrent connections, then act surprised when everything grinds to a halt.
JobRunr pro gets it. It understands that your database is not an infinite resource and treats it with the respect it deserves. No connection pool exhaustion. No lock contention nightmares. No “why is my database CPU at 100% when I’m only processing 50 jobs?” moments. This is especially crucial in banking applications where your database is often shared with real-time transaction processing.
The last thing you want is your background job to process monthly statements interfering with calculating a real-time fee.
The Features That Actually Mattered for Us
JobFilters
This is where JobRunr Pro shows its distributed systems maturity. When you’re running jobs across multiple nodes in a cluster, thread-local variables become… complicated. Add multi-tenancy to the mix (because of course we’re multi-tenant), and JobFilters become absolutely essential.
They handle this elegantly, letting you maintain context without losing your sanity. It’s the kind of feature you don’t appreciate until you need it, and then you can’t live without it.
class UserContextClientFilter : JobClientFilter {
private val logger = LoggerFactory.getLogger(javaClass)
override fun onCreating(job: AbstractJob?) {
logger.debug("Capturing user context for job creation")
val jobInstance = job as? Job
jobInstance?.metadata?.apply {
put("userId", UserContext.getCurrentUserId())
put("organizationId", UserContext.getOrganizationId())
}
}
}
class UserContextServerFilter : JobServerFilter {
private val logger = LoggerFactory.getLogger(javaClass)
override fun onProcessing(job: Job?) {
logger.debug("Restoring user context for job processing")
val jobInstance = job as? Job
jobInstance?.metadata?.let { metadata ->
val userId = metadata["userId"]?.toString()
val organizationId = metadata["organizationId"]?.toString()
userId?.let { UserContext.setUserId(it) }
organizationId?.let { UserContext.setOrganizationId(it) }
}
}
}
Job Dependencies & Workflows
This is where JobRunr Pro really shines for complex financial operations. Being able to define job dependencies means we can orchestrate multi-step processes without the usual coordination headaches. The parent job functionality gave us a solid foundation, but we sprinkled some extra magic on top to make chunking easier.
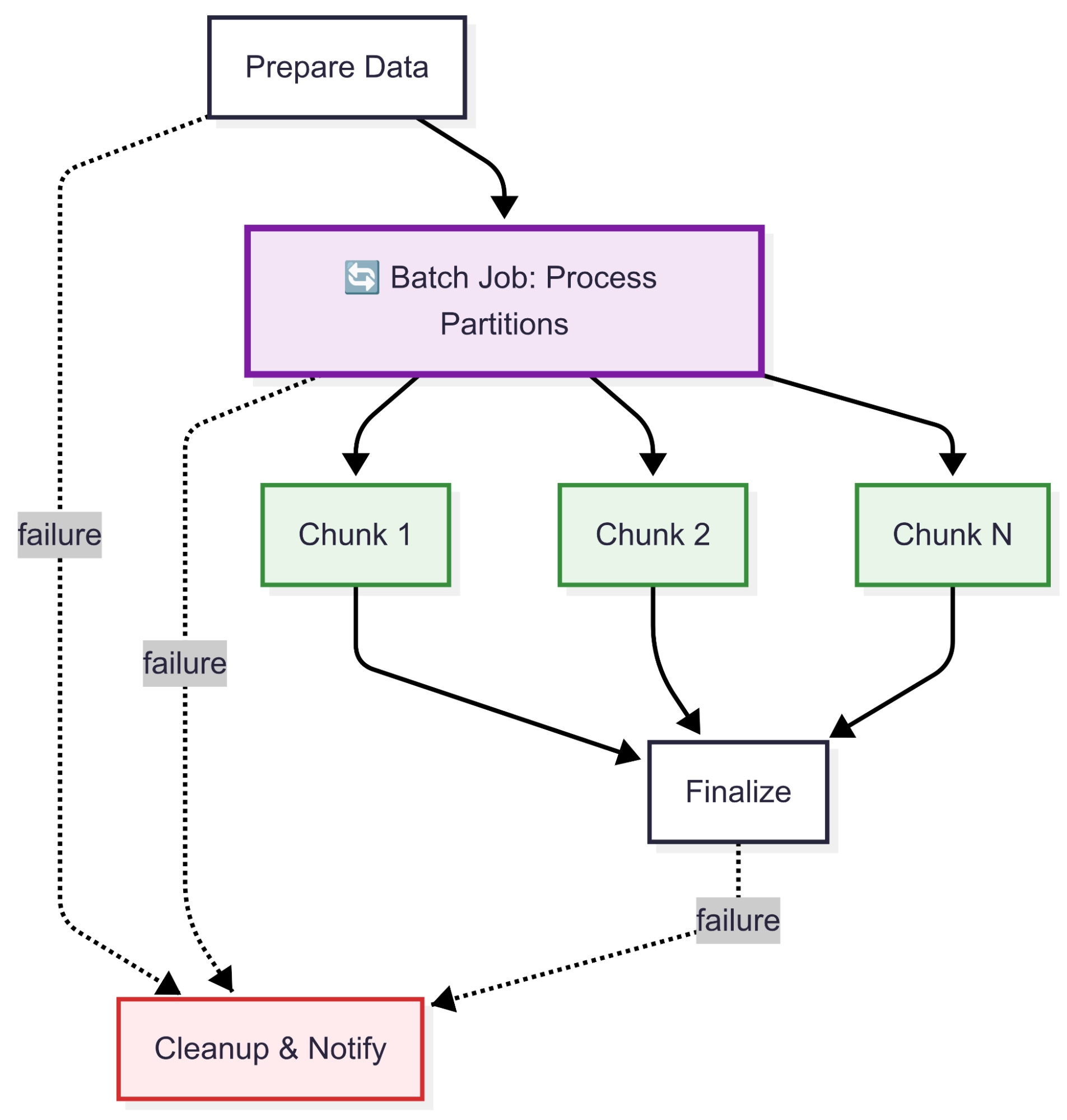
override fun startProcessingWorkflow(batchId: String): JobProId {
logger.info("Starting data processing workflow for batch: {}", batchId)
// Step 1: Staging table with filtered data
val preparationJobId = jobScheduler.create(
JobBuilder.aJob()
.withName("Data Preparation")
.withLabels("batch-$batchId")
.withAmountOfRetries(2)
.withDetails { prepareStagingTable(batchId) }
)
// Step 2: Create partitions and process chunks
val partitionJobId = jobScheduler.create(
JobBuilder.aBatchJob()
.withName("Data Partition Processing")
.withLabels("batch-$batchId")
.withAmountOfRetries(1)
.runAfter(preparationJobId)
.withDetails { createAndProcessPartitions(batchId) }
)
// Step 3: Finalize batch
val finalizationJobId = jobScheduler.create(
JobBuilder.aJob()
.withName("Batch Finalization")
.withLabels("batch-$batchId")
.withAmountOfRetries(3)
.runAfter(partitionJobId)
.withDetails { finalizeBatch(batchId) }
)
// Register failure handlers
preparationJobId.onFailure { handleProcessingFailure(batchId, "PREPARATION_FAILED") }
partitionJobId.onFailure { handleProcessingFailure(batchId, "PARTITION_FAILED") }
finalizationJobId.onFailure { handleProcessingFailure(batchId, "FINALIZATION_FAILED") }
logger.info("Created processing workflow with ID: {} for batch: {}", finalizationJobId, batchId)
return finalizationJobId
}
Take invoice generation, for example. We need to calculate all fees for the period, apply any promotional discounts, generate invoice files, and then send notifications.
With JobRunr Pro’s workflow capabilities, we can chain these steps together elegantly—if fee calculation fails, we don’t waste time generating invoice files. If invoice generation succeeds but notification fails, we can retry just the notification step. It’s like having a state machine, but without the complexity.
Priority Queues
In fintech, latency isn’t just an annoyance; it’s a liability. We learned the hard way that in a mixed-workload environment, you cannot treat a user waiting for a One-Time Password (OTP) the same way you treat a nightly report generation task.
If your background workers are clogged up processing 50,000 monthly statements, that single critical fraud alert or password reset email shouldn’t have to wait in line. JobRunr Pro solves this with Priority Queues, allowing us to let high-value, time-sensitive transactions “skip the line” automatically.
It’s like having a dedicated express lane for VIP traffic without the overhead of managing completely separate infrastructure clusters.
// High Priority: The user is literally waiting at the screen
jobScheduler.create(
aJob()
.withName("Send Authorization OTP")
.withQueue("High-prio") // Top priority
.withDetails(() -> notificationService.sendHighPriorityOtp(userId))
);
// Standard Priority: Business as usual
jobScheduler.create(
aJob()
.withName("Send Authorization OTP")
.withQueue("Default") // Default priority
.withDetails(() -> feeService.calculate(transactionId))
);
// Low Priority: "Get to it when the server is bored"
jobScheduler.create(
aJob()
.withName("Generate Monthly Statement PDF")
.withQueue("LowPrio") // Background fill
.withDetails (() -> statementService.generatePdf(accountId))
);
This simple withQueue argument saved us from the “noisy neighbor” problem. Now, no matter how heavy our batch processing gets, real-time customer interactions always take precedence.
Spring Boot Integration
At Fincarna, we’re pretty much a Spring shop, we love the ecosystem, the conventions, and how everything just works together.
JobRunr Pro’s seamless Spring Boot integration means we didn’t have to fight our existing architecture or learn a completely new way of doing things. Configuration is clean, dependency injection works as expected, and our job classes fit naturally into our existing Spring context.
Kubernetes Vision
While we’re currently using our own container orchestration approach at Fincarna, knowing that JobRunr Pro is built with Kubernetes in mind gives me confidence for future scaling decisions. When we do evaluate different orchestration strategies, we won’t need to rethink our entire job processing architecture.
The Bottom Line
Look, sure, I could spend months building yet another custom job processing system. I’ve been down that road before. But at some point, you realize that job processing is not your competitive advantage - building better financial products is.
JobRunr Pro lets me focus on the problems that actually matter: How do we provide the tools and arsenal for small banks to think big and aim high? How do we make complex monetization operations simple? How do we build systems that are both innovative and compliant?
These are the problems worth solving. Everything else should just work.
Ready to take control of your background jobs?
Stop wrestling with frameworks that weren’t built for your use case. Discover how JobRunr Pro can simplify your architecture, scale with your needs, and let you focus on what you do best.
Lloyd Chandran is the founder and lead architect of Fincarna, a cutting-edge, cloud-native monetization platform helping small and medium banks compete in the digital age. When he’s not building Fincarna’s next feature, he’s probably debugging why his lawn mower isn’t working (again).
